「11月28日 农历十月十六 星期二」,那是一个风很安静的下午,我喝着咖啡,唱着歌,收到了来自客户的反馈
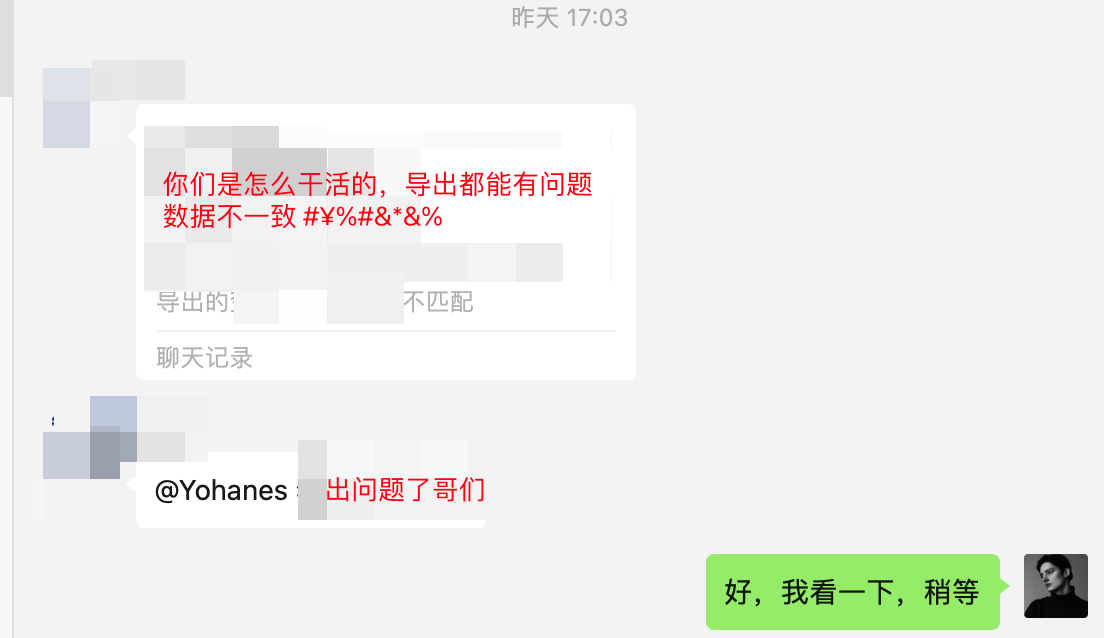
说我们在页面展示的效果和导出后的数据不匹配,我内心一想,不应该啊。我亲自导出了一下,好家伙,连格式都是错乱的

📌生产数据以及代码较为敏感,这里为模拟代码
不过事已至此,唯有埋头苦干,抱怨是没用的。尽早把问题解决出来,再找到写代码的人痛骂一顿才是正事,上代码
public static void export(HttpServletResponse response) {
//excel数据集合
List<UserDTO> excelData = getData();
//调用内部封装的export方法
EasyExcelUtil.export("用户信息", excelData, UserExcelVo.class, response);
}
这是整个excel导出的逻辑,debug先看一下excelData的数据是否正常
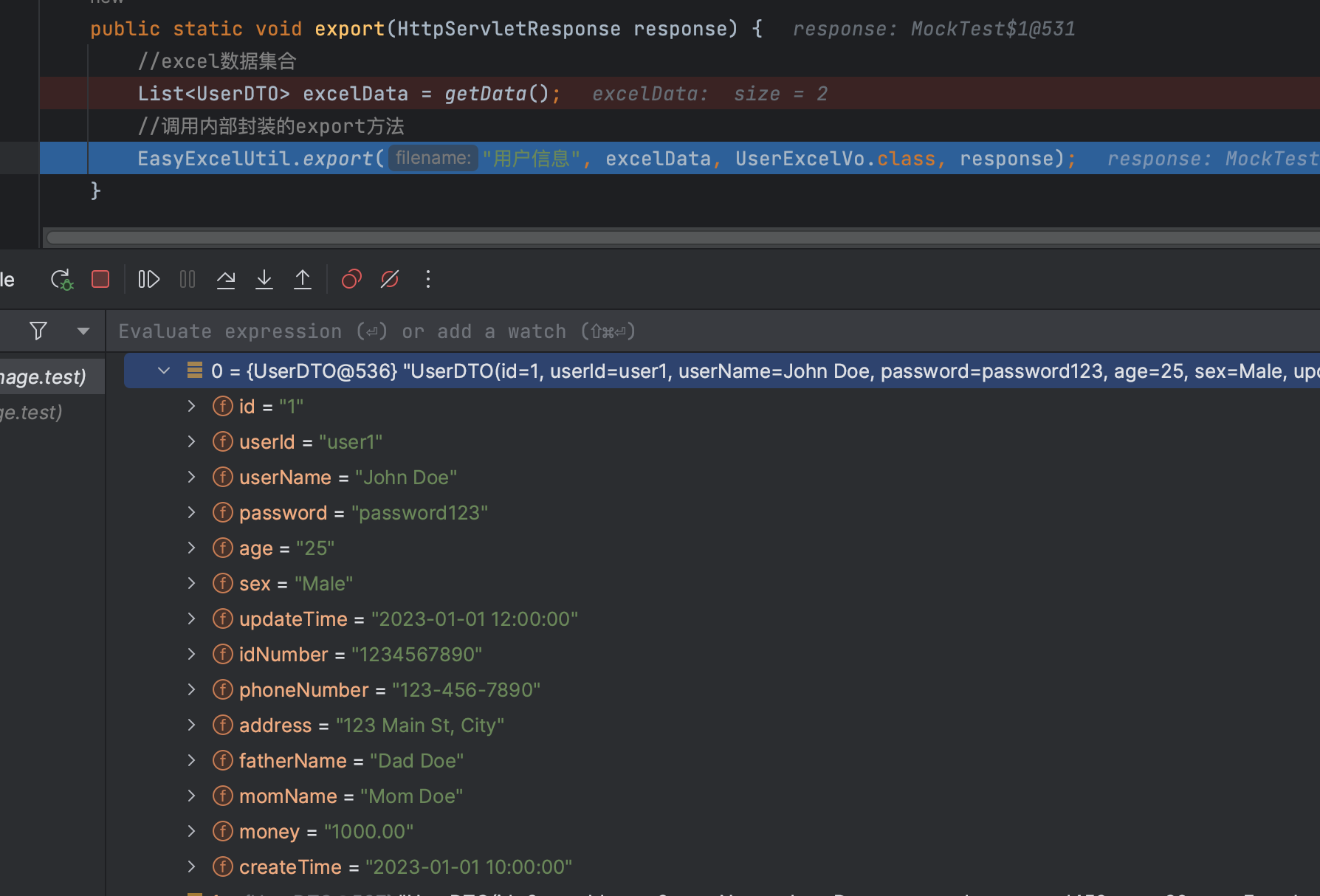
看起来一切顺利,但是为什么就是最后 导出的结果是这样呢

这是我的UserExcelVo,看完我就懵了,为什么我的用户id明明对应的是userId,最后出来的确实data里的id 字段呢?然后仔细检查一下,发现貌似所有的地方都��错了,纳闷!(这里可能错的有些明显,实际上生产只有一个字段错了,其他的都是对的!!)
@Data
@HeadStyle(horizontalAlignment = HorizontalAlignment.CENTER) //表头样式
@HeadFontStyle(fontHeightInPoints = 10) //表头字体大小
@ContentStyle(horizontalAlignment = HorizontalAlignment.CENTER) //内容样式
public class UserExcelVo implements Serializable {
private static final long serialVersionUID = 1L;
//项目编号
@ColumnWidth(10)
@ExcelProperty(value = "用户id", index = 0)
private String userId;
@ColumnWidth(10)
@ExcelProperty(value = "用户姓名", index = 1)
private String userName;
@ColumnWidth(10)
@ExcelProperty(value = "年龄", index = 2)
private String age;
@ColumnWidth(15)
@ExcelProperty(value = "性别", index = 3)
private String sex;
@ColumnWidth(10)
@ExcelProperty(value = "身份证", index = 4)
private String idNumber;
@ColumnWidth(10)
@ExcelProperty(value = "手机号", index = 5)
private String phoneNumber;
@ColumnWidth(10)
@ExcelProperty(value = "户籍所在地", index = 6)
private String address;
@ColumnWidth(15)
@ExcelProperty(value = "父亲", index = 7)
private String fatherName;
@ColumnWidth(10)
@ExcelProperty(value = "母亲", index = 8)
private String momName;
@ColumnWidth(10)
@ExcelProperty(value = "财产", index = 9)
private String money;
}
到了这里,我就郁闷了,看起来还是excelUtils的锅啊,不过作为一名专业的开发人员,必须体现出自己的专业素养。「人家有的是背景,咱有的是背影」 不慌。嗷嗷就是干,打开utils看一看,具体怎么写的
public static void export(String filename, List<?> dataResult, Class<?> clazz, HttpServletResponse response) {
response.setStatus(200);
OutputStream outputStream = null;
ExcelWriter excelWriter = null;
try {
if (StringUtils.isBlank(filename)) {
throw new RuntimeException("'filename' 不能为空");
}
String fileName = filename.concat(".xlsx");
response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(fileName, "utf-8"));
response.setContentType("application/vnd.ms-excel;charset=utf-8");
response.setCharacterEncoding("utf-8");
outputStream = response.getOutputStream();
// 根据不同的策略生成不同的ExcelWriter对象
if (dataResult == null){
excelWriter = getTemplateExcelWriter(outputStream);
} else {
excelWriter = getExportExcelWriter(outputStream);
}
WriteTable writeTable = EasyExcel.writerTable(0).head(clazz).needHead(true).build();
WriteSheet writeSheet = EasyExcel.writerSheet(fileName).build();
// 写出数据
excelWriter.write(dataResult, writeSheet, writeTable);
} catch (Exception e) {
log.error("导出excel数据异常:", e);
throw new RuntimeException(e);
} finally {
if (excelWriter != null) {
excelWriter.finish();
}
if (outputStream != null) {
try {
outputStream.flush();
outputStream.close();
} catch (IOException e) {
log.error("导出数据关闭流异常", e);
}
}
}
}
private static ExcelWriter getExportExcelWriter(OutputStream outputStream){
return EasyExcel.write(outputStream)
.registerWriteHandler(getStyleStrategy()) //字体居中策略
.build();
}
为了以防万一,到最后write写入的时候,再看一眼,数据是不是发生了变化,类是不是搞错了?
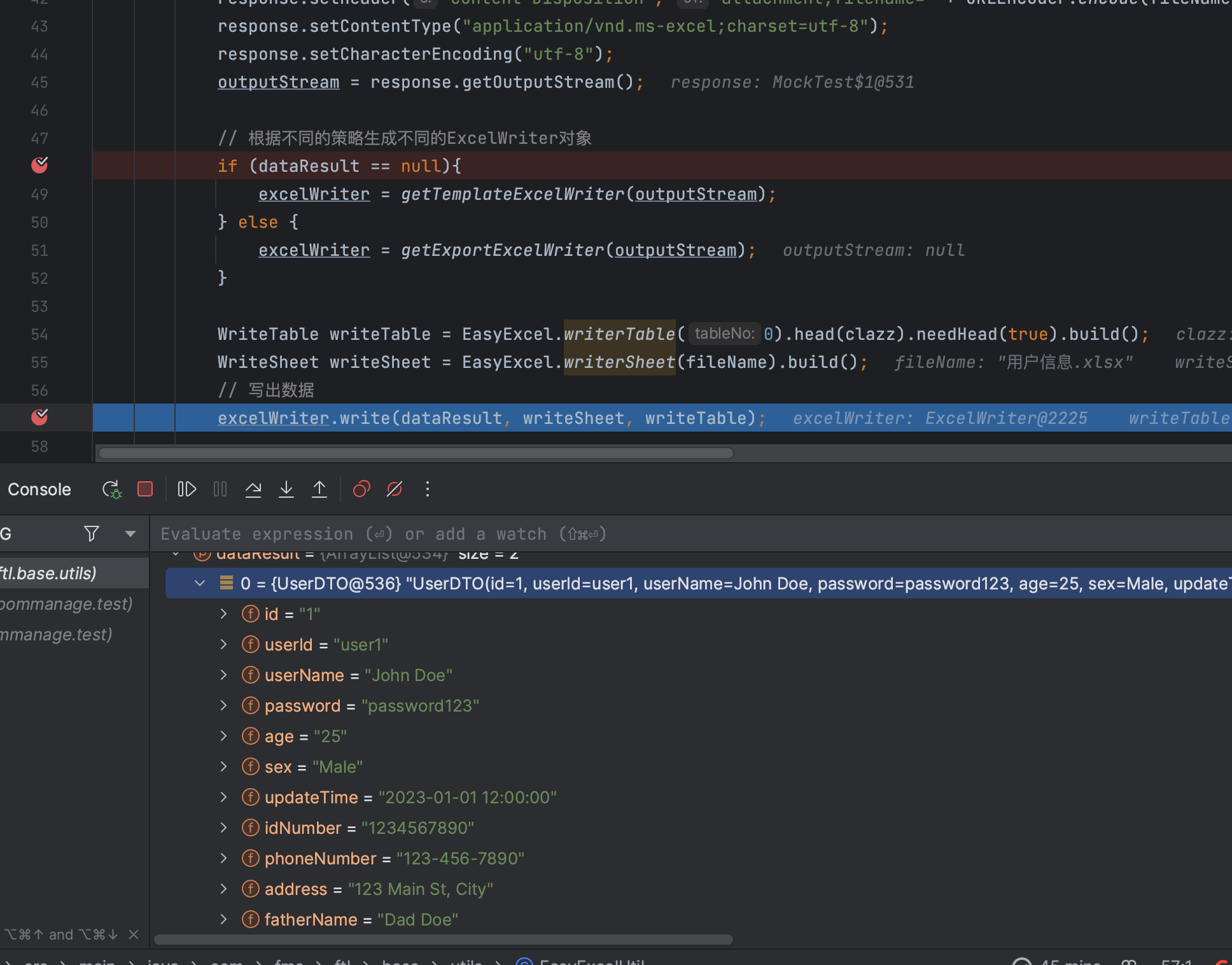
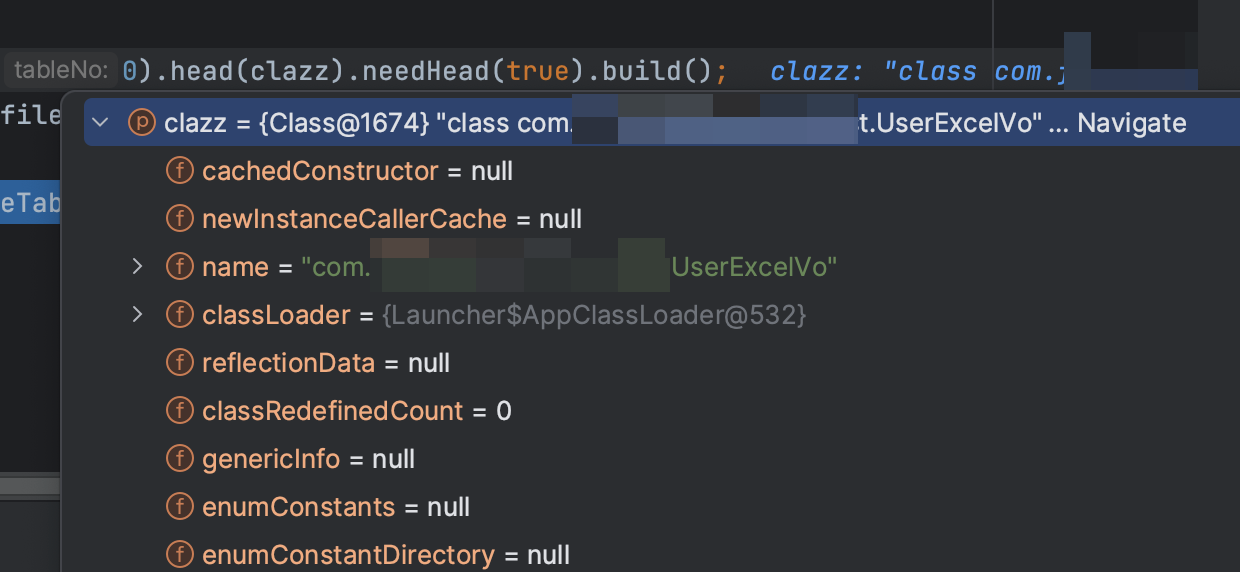
嗯。。数据也没错,类也没错,我的内心 ???啊? why ? 数据没错啊。
看样子代码好像也没什么大问题啊?而且之前这个导出为什么别人没问题,就这个代码有问题,为什么,什么鬼,灵异事件?
到了这一步,我猜测,可能是easyExcel出的bug,但我并不确定,但是为了排除这个问题,我将excelExcel升了两个小版本,本来是2.2.7,升级到了2.2.11
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.2.7</version>
</dependency>
这也是2系列的最后一个版本,如果升级到3,api变化较大,而且底层的poi版本也做了升级,我们不仅仅只有一个easyexcel,还有一个自研的excel导出,因此,只能做小版本升级
升级完成以后,果然! 没有果然,还是失败。。

不甘心的我,再次检查,显微镜逐行阅读方法,好像真的没什么问题啊,我开始慌了!!怎�么办,好像不是代码问题?但是easyexcel也升级了还是有问题,难道easyexcel一直存在这个问题?不应该啊
衣带渐宽终不悔,Bug 寻得人憔悴。
年少太轻狂,误入 IT 行,
白发森森立,两眼直茫茫。
语言数十种,无一称擅长。
三十而立时,无房单身郎。
此时此刻我只有两个选择,要么穿上衬衫,键击代码框。要么骑上三轮,收旧冰箱。
不是三轮不好骑,而是衬衫更有性价比
猛🦌一口气,开始debug源码
先看一下excelWriter ,一看就没有核心逻辑,不看不看,直接到下面
private static ExcelWriter getTemplateExcelWriter(OutputStream outputStream){
return EasyExcel.write(outputStream)
// .registerWriteHandler(new CommentWriteHandler()) //增加批注策略
// .registerWriteHandler(new CustomSheetWriteHandler()) //增加下拉框策略
.registerWriteHandler(getStyleStrategy()) //字体居中策略
.build();
}
直接看写入的。。
excelWriter.write(dataResult, writeSheet, writeTable);
public ExcelWriter write(List data, WriteSheet writeSheet, WriteTable writeTable) {
excelBuilder.addContent(data, writeSheet, writeTable);
return this;
}
嗯,addContent 一看就是我想要的,宝 我来啦
public void addContent(List data, WriteSheet writeSheet, WriteTable writeTable) {
try {
context.currentSheet(writeSheet, WriteTypeEnum.ADD);
context.currentTable(writeTable);
if (excelWriteAddExecutor == null) {
excelWriteAddExecutor = new ExcelWriteAddExecutor(context);
}
excelWriteAddExecutor.add(data);
} catch (RuntimeException e) {
finishOnException();
throw e;
} catch (Throwable e) {
finishOnException();
throw new ExcelGenerateException(e);
}
}
纳尼,芥末多? ok 不怕,我们一个一个来,作为一名专业的程序员,一定要稳如泰山
@Override
public void currentSheet(WriteSheet writeSheet, WriteTypeEnum writeType) {
if (writeSheet == null) {
throw new IllegalArgumentException("Sheet argument cannot be null");
}
if (selectSheetFromCache(writeSheet)) {
return;
}
initCurrentSheetHolder(writeSheet);
// Workbook handler need to supplementary execution
WriteHandlerUtils.beforeWorkbookCreate(this, true);
WriteHandlerUtils.afterWorkbookCreate(this, true);
// Initialization current sheet
initSheet(writeType);
}
我的眼光,聚焦在四个方法
initCurrentSheetHolder(writeSheet);WriteHandlerUtils.beforeWorkbookCreate(this, true);WriteHandlerUtils.afterWorkbookCreate(this, true);initSheet(writeType);
如果有我需要的代码,也一定是在这四个方法内,ok 让我们细细品尝
private void initCurrentSheetHolder(WriteSheet writeSheet) {
//可能构造器内部有逻辑?
writeSheetHolder = new WriteSheetHolder(writeSheet, writeWorkbookHolder);
//下面平平无奇,不用看了
writeTableHolder = null;
currentWriteHolder = writeSheetHolder;
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("CurrentConfiguration is writeSheetHolder");
}
}
/**
* 构造函数,初始化 WriteSheetHolder 对象
*
* @param writeSheet 写入的工作表信息
* @param writeWorkbookHolder 写入的工作簿信息持有者
*/
public WriteSheetHolder(WriteSheet writeSheet, WriteWorkbookHolder writeWorkbookHolder) {
// 调用父类的构造函数进行初始化
super(writeSheet, writeWorkbookHolder, writeWorkbookHolder.getWriteWorkbook().getConvertAllFiled());
// 初始化 WriteSheetHolder 对象的属性
this.writeSheet = writeSheet;
// 根据工作表的编号和名称初始化 sheetNo 和 sheetName
if (writeSheet.getSheetNo() == null && StringUtils.isEmpty(writeSheet.getSheetName())) {
this.sheetNo = 0;
} else {
this.sheetNo = writeSheet.getSheetNo();
}
this.sheetName = writeSheet.getSheetName();
// 记录父级 WriteWorkbookHolder
this.parentWriteWorkbookHolder = writeWorkbookHolder;
// 初始化表格已被初始化的标记集合
this.hasBeenInitializedTable = new HashMap<Integer, WriteTableHolder>();
// 根据模板输入流是否为空初始化写入的最后一行的类型
if (writeWorkbookHolder.getTempTemplateInputStream() != null) {
writeLastRowTypeEnum = WriteLastRowTypeEnum.TEMPLATE_EMPTY;
} else {
writeLastRowTypeEnum = WriteLastRowTypeEnum.COMMON_EMPTY;
}
}
我加上了注释,但好像看起来也没有相对应的逻辑? why? 但请注意,作为一名专业的程序员,我们应该知道不放弃任何一个细节,看第一句话,他调用了父类的构造器,在进行了初始化,所以我们还要在看一下父类的
/**
* 构造函数,初始化 AbstractWriteHolder 对象
*
* @param writeBasicParameter 写入基本参数
* @param parentAbstractWriteHolder 父级 AbstractWriteHolder 对象
* @param convertAllFiled 是否转换所有字段
*/
public AbstractWriteHolder(WriteBasicParameter writeBasicParameter, AbstractWriteHolder parentAbstractWriteHolder,
Boolean convertAllFiled) {
// 调用父类的构造函数进行初始化
super(writeBasicParameter, parentAbstractWriteHolder);
// 根据 use1904windowing 初始化全局配置
if (writeBasicParameter.getUse1904windowing() == null) {
if (parentAbstractWriteHolder == null) {
getGlobalConfiguration().setUse1904windowing(Boolean.FALSE);
} else {
getGlobalConfiguration()
.setUse1904windowing(parentAbstractWriteHolder.getGlobalConfiguration().getUse1904windowing());
}
} else {
getGlobalConfiguration().setUse1904windowing(writeBasicParameter.getUse1904windowing());
}
// 不支持 useScientificFormat 的设置,抛出异常
if (writeBasicParameter.getUseScientificFormat() != null) {
throw new UnsupportedOperationException("Currently does not support setting useScientificFormat.");
}
// 根据 needHead 初始化是否需要表头
if (writeBasicParameter.getNeedHead() == null) {
if (parentAbstractWriteHolder == null) {
this.needHead = Boolean.TRUE;
} else {
this.needHead = parentAbstractWriteHolder.getNeedHead();
}
} else {
this.needHead = writeBasicParameter.getNeedHead();
}
// 根据 relativeHeadRowIndex 初始化相对表头的行索引
if (writeBasicParameter.getRelativeHeadRowIndex() == null) {
if (parentAbstractWriteHolder == null) {
this.relativeHeadRowIndex = 0;
} else {
this.relativeHeadRowIndex = parentAbstractWriteHolder.getRelativeHeadRowIndex();
}
} else {
this.relativeHeadRowIndex = writeBasicParameter.getRelativeHeadRowIndex();
}
// 根据 useDefaultStyle 初始化是否使用默认样式
if (writeBasicParameter.getUseDefaultStyle() == null) {
if (parentAbstractWriteHolder == null) {
this.useDefaultStyle = Boolean.TRUE;
} else {
this.useDefaultStyle = parentAbstractWriteHolder.getUseDefaultStyle();
}
} else {
this.useDefaultStyle = writeBasicParameter.getUseDefaultStyle();
}
// 根据 automaticMergeHead 初始化是否自动合并表头
if (writeBasicParameter.getAutomaticMergeHead() == null) {
if (parentAbstractWriteHolder == null) {
this.automaticMergeHead = Boolean.TRUE;
} else {
this.automaticMergeHead = parentAbstractWriteHolder.getAutomaticMergeHead();
}
} else {
this.automaticMergeHead = writeBasicParameter.getAutomaticMergeHead();
}
// 根据 excludeColumnFiledNames 初始化排除的列字段名集合
if (writeBasicParameter.getExcludeColumnFiledNames() == null && parentAbstractWriteHolder != null) {
this.excludeColumnFiledNames = parentAbstractWriteHolder.getExcludeColumnFiledNames();
} else {
this.excludeColumnFiledNames = writeBasicParameter.getExcludeColumnFiledNames();
}
// 根据 excludeColumnIndexes 初始化排除的列索引集合
if (writeBasicParameter.getExcludeColumnIndexes() == null && parentAbstractWriteHolder != null) {
this.excludeColumnIndexes = parentAbstractWriteHolder.getExcludeColumnIndexes();
} else {
this.excludeColumnIndexes = writeBasicParameter.getExcludeColumnIndexes();
}
// 根据 includeColumnFiledNames 初始化包含的列字段名集合
if (writeBasicParameter.getIncludeColumnFiledNames() == null && parentAbstractWriteHolder != null) {
this.includeColumnFiledNames = parentAbstractWriteHolder.getIncludeColumnFiledNames();
} else {
this.includeColumnFiledNames = writeBasicParameter.getIncludeColumnFiledNames();
}
// 根据 includeColumnIndexes 初始化包含的列索引集合
if (writeBasicParameter.getIncludeColumnIndexes() == null && parentAbstractWriteHolder != null) {
this.includeColumnIndexes = parentAbstractWriteHolder.getIncludeColumnIndexes();
} else {
this.includeColumnIndexes = writeBasicParameter.getIncludeColumnIndexes();
}
// 初始化 ExcelWriteHeadProperty 对象
this.excelWriteHeadProperty = new ExcelWriteHeadProperty(this, getClazz(), getHead(), convertAllFiled);
// 兼容旧的代码
compatibleOldCode(writeBasicParameter);
// 设置 writeHandlerMap
List<WriteHandler> handlerList = new ArrayList<WriteHandler>();
// 初始化注解配置
initAnnotationConfig(handlerList, writeBasicParameter);
// 添加自定义的 WriteHandler 列表
if (writeBasicParameter.getCustomWriteHandlerList() != null
&& !writeBasicParameter.getCustomWriteHandlerList().isEmpty()) {
handlerList.addAll(writeBasicParameter.getCustomWriteHandlerList());
}
// 初始化 ownWriteHandlerMap
this.ownWriteHandlerMap = sortAndClearUpHandler(handlerList);
// 初始化父级 WriteHandlerMap
Map<Class<? extends WriteHandler>, List<WriteHandler>> parentWriteHandlerMap = null;
if (parentAbstractWriteHolder != null) {
parentWriteHandlerMap = parentAbstractWriteHolder.getWriteHandlerMap();
} else {
handlerList.addAll(DefaultWriteHandlerLoader.loadDefaultHandler(useDefaultStyle));
}
// 初始化 writeHandlerMap
this.writeHandlerMap = sortAndClearUpAllHandler(handlerList, parentWriteHandlerMap);
// 设置 converterMap
if (parentAbstractWriteHolder == null) {
// 如果没有父级 AbstractWriteHolder,加载默认的 WriteConverter
setConverterMap(DefaultConverterLoader.loadDefaultWriteConverter());
} else {
// 如果有父级 AbstractWriteHolder,复制父级的 ConverterMap
setConverterMap(new HashMap<String, Converter>(parentAbstractWriteHolder.getConverterMap()));
}
// 添加自定义的 Converter 列表
if (writeBasicParameter.getCustomConverterList() != null
&& !writeBasicParameter.getCustomConverterList().isEmpty()) {
for (Converter converter : writeBasicParameter.getCustomConverterList()) {
// 根据支持的 Java 类型构建 key,并将 Converter 加入到 map 中
getConverterMap().put(ConverterKeyBuild.buildKey(converter.supportJavaTypeKey()), converter);
}
}
}
此时的我已经身心疲惫,检查一下堆栈信息中的类,是否有我想要的信息
看了看对应的handler,并没有什么信息
如果没有办法一眼就能看出各个类型大体是干什么的,就得慢慢debug看了,没辙,一步一步来吧

这里我关注到了这一行
// Initialization property
this.excelWriteHeadProperty = new ExcelWriteHeadProperty(this, getClazz(), getHead(), convertAllFiled);
哦??听名字,就是我想要的样子~ 获取写入头的属性
public ExcelWriteHeadProperty(Holder holder, Class headClazz, List<List<String>> head, Boolean convertAllFiled) {
super(holder, headClazz, head, convertAllFiled);
if (getHeadKind() != HeadKindEnum.CLASS) {
return;
}
this.headRowHeightProperty =
RowHeightProperty.build((HeadRowHeight) headClazz.getAnnotation(HeadRowHeight.class));
this.contentRowHeightProperty =
RowHeightProperty.build((ContentRowHeight) headClazz.getAnnotation(ContentRowHeight.class));
this.onceAbsoluteMergeProperty =
OnceAbsoluteMergeProperty.build((OnceAbsoluteMerge) headClazz.getAnnotation(OnceAbsoluteMerge.class));
ColumnWidth parentColumnWidth = (ColumnWidth) headClazz.getAnnotation(ColumnWidth.class);
HeadStyle parentHeadStyle = (HeadStyle) headClazz.getAnnotation(HeadStyle.class);
HeadFontStyle parentHeadFontStyle = (HeadFontStyle) headClazz.getAnnotation(HeadFontStyle.class);
ContentStyle parentContentStyle = (ContentStyle) headClazz.getAnnotation(ContentStyle.class);
ContentFontStyle parentContentFontStyle = (ContentFontStyle) headClazz.getAnnotation(ContentFontStyle.class);
for (Map.Entry<Integer, ExcelContentProperty> entry : getContentPropertyMap().entrySet()) {
Integer index = entry.getKey();
ExcelContentProperty excelContentPropertyData = entry.getValue();
if (excelContentPropertyData == null) {
throw new IllegalArgumentException(
"Passing in the class and list the head, the two must be the same size.");
}
Field field = excelContentPropertyData.getField();
Head headData = getHeadMap().get(index);
ColumnWidth columnWidth = field.getAnnotation(ColumnWidth.class);
if (columnWidth == null) {
columnWidth = parentColumnWidth;
}
headData.setColumnWidthProperty(ColumnWidthProperty.build(columnWidth));
HeadStyle headStyle = field.getAnnotation(HeadStyle.class);
if (headStyle == null) {
headStyle = parentHeadStyle;
}
headData.setHeadStyleProperty(StyleProperty.build(headStyle));
HeadFontStyle headFontStyle = field.getAnnotation(HeadFontStyle.class);
if (headFontStyle == null) {
headFontStyle = parentHeadFontStyle;
}
headData.setHeadFontProperty(FontProperty.build(headFontStyle));
ContentStyle contentStyle = field.getAnnotation(ContentStyle.class);
if (contentStyle == null) {
contentStyle = parentContentStyle;
}
headData.setContentStyleProperty(StyleProperty.build(contentStyle));
ContentFontStyle contentFontStyle = field.getAnnotation(ContentFontStyle.class);
if (contentFontStyle == null) {
contentFontStyle = parentContentFontStyle;
}
headData.setContentFontProperty(FontProperty.build(contentFontStyle));
headData.setLoopMergeProperty(LoopMergeProperty.build(field.getAnnotation(ContentLoopMerge.class)));
// If have @NumberFormat, 'NumberStringConverter' is specified by default
if (excelContentPropertyData.getConverter() == null) {
NumberFormat numberFormat = field.getAnnotation(NumberFormat.class);
if (numberFormat != null) {
excelContentPropertyData.setConverter(DefaultConverterLoader.loadAllConverter()
.get(ConverterKeyBuild.buildKey(field.getType(), CellDataTypeEnum.STRING)));
}
}
}
}
然后还是构造器
public ExcelHeadProperty(Holder holder, Class headClazz, List<List<String>> head, Boolean convertAllFiled) {
this.headClazz = headClazz;
headMap = new TreeMap<Integer, Head>();
contentPropertyMap = new TreeMap<Integer, ExcelContentProperty>();
fieldNameContentPropertyMap = new HashMap<String, ExcelContentProperty>();
ignoreMap = new HashMap<String, Field>(16);
headKind = HeadKindEnum.NONE;
headRowNumber = 0;
if (head != null && !head.isEmpty()) {
int headIndex = 0;
for (int i = 0; i < head.size(); i++) {
if (holder instanceof AbstractWriteHolder) {
if (((AbstractWriteHolder) holder).ignore(null, i)) {
continue;
}
}
headMap.put(headIndex, new Head(headIndex, null, head.get(i), Boolean.FALSE, Boolean.TRUE));
contentPropertyMap.put(headIndex, null);
headIndex++;
}
headKind = HeadKindEnum.STRING;
}
// convert headClazz to head
initColumnProperties(holder, convertAllFiled);
initHeadRowNumber();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("The initialization sheet/table 'ExcelHeadProperty' is complete , head kind is {}", headKind);
}
}
initColumnProperties(holder, convertAllFiled); 这里初始化字段属性
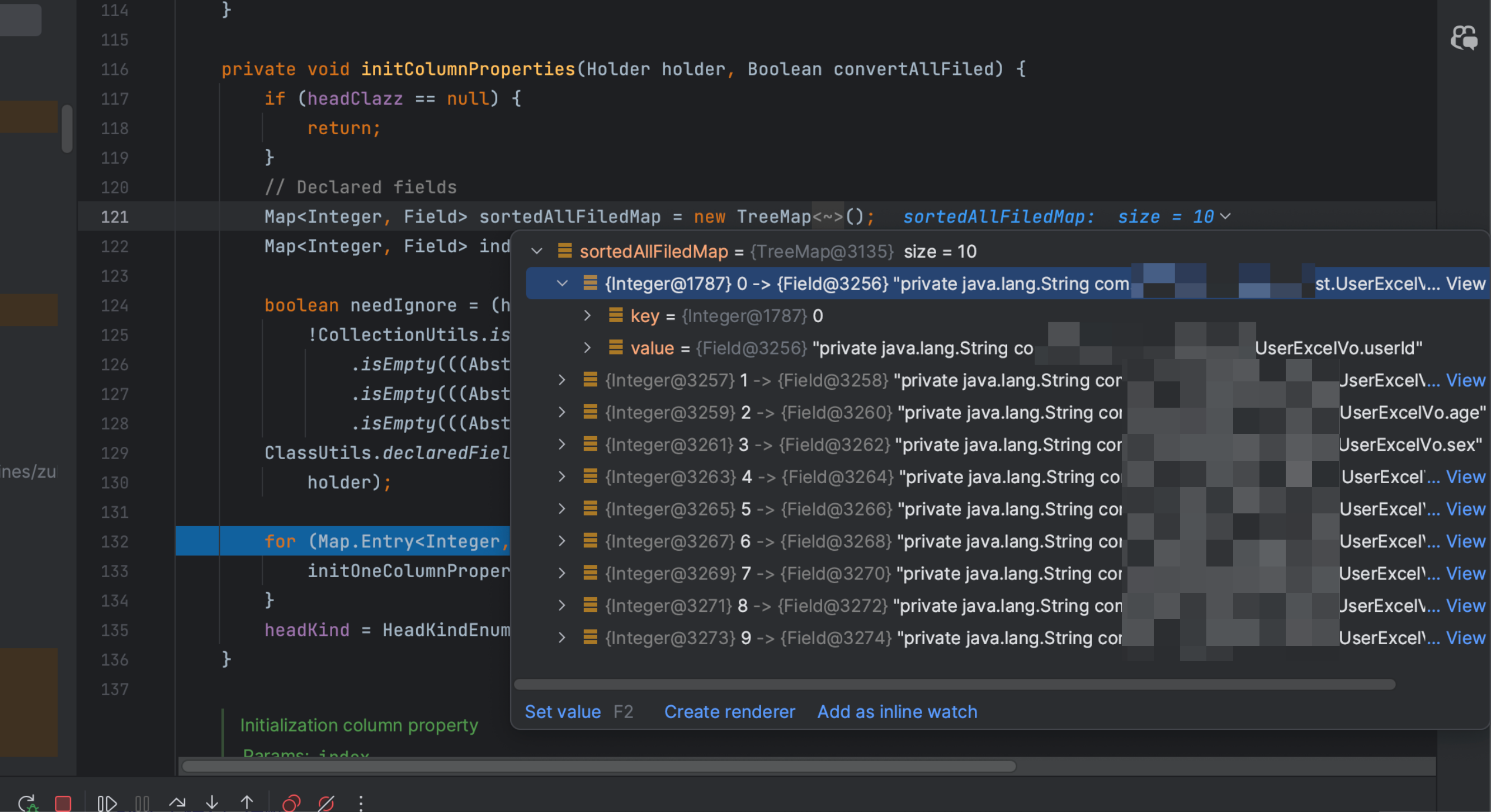
可以看到,他拿到的属性,的确是我们UserExcelVo的十个属性, 看起来一切都是正常的,是我们想要的
然后他又做了一个for循环,我们看看内部如何去做的,也就是这些
private void initOneColumnProperty(int index, Field field, Boolean forceIndex) {
ExcelProperty excelProperty = field.getAnnotation(ExcelProperty.class);
List<String> tmpHeadList = new ArrayList<String>();
boolean notForceName = excelProperty == null || excelProperty.value().length <= 0
|| (excelProperty.value().length == 1 && StringUtils.isEmpty((excelProperty.value())[0]));
if (headMap.containsKey(index)) {
tmpHeadList.addAll(headMap.get(index).getHeadNameList());
} else {
if (notForceName) {
tmpHeadList.add(field.getName());
} else {
Collections.addAll(tmpHeadList, excelProperty.value());
}
}
Head head = new Head(index, field.getName(), tmpHeadList, forceIndex, !notForceName);
ExcelContentProperty excelContentProperty = new ExcelContentProperty();
if (excelProperty != null) {
Class<? extends Converter> convertClazz = excelProperty.converter();
if (convertClazz != AutoConverter.class) {
try {
Converter converter = convertClazz.newInstance();
excelContentProperty.setConverter(converter);
} catch (Exception e) {
throw new ExcelCommonException("Can not instance custom converter:" + convertClazz.getName());
}
}
}
excelContentProperty.setHead(head);
excelContentProperty.setField(field);
excelContentProperty
.setDateTimeFormatProperty(DateTimeFormatProperty.build(field.getAnnotation(DateTimeFormat.class)));
excelContentProperty
.setNumberFormatProperty(NumberFormatProperty.build(field.getAnnotation(NumberFormat.class)));
headMap.put(index, head);
contentPropertyMap.put(index, excelContentProperty);
fieldNameContentPropertyMap.put(field.getName(), excelContentProperty);
}
可以看到,他是根据@ExcelProperty注解去做的一个检查操作,最后搞到Head中,这个Head很重要哈
然后将head转换成ExcelContentProperty
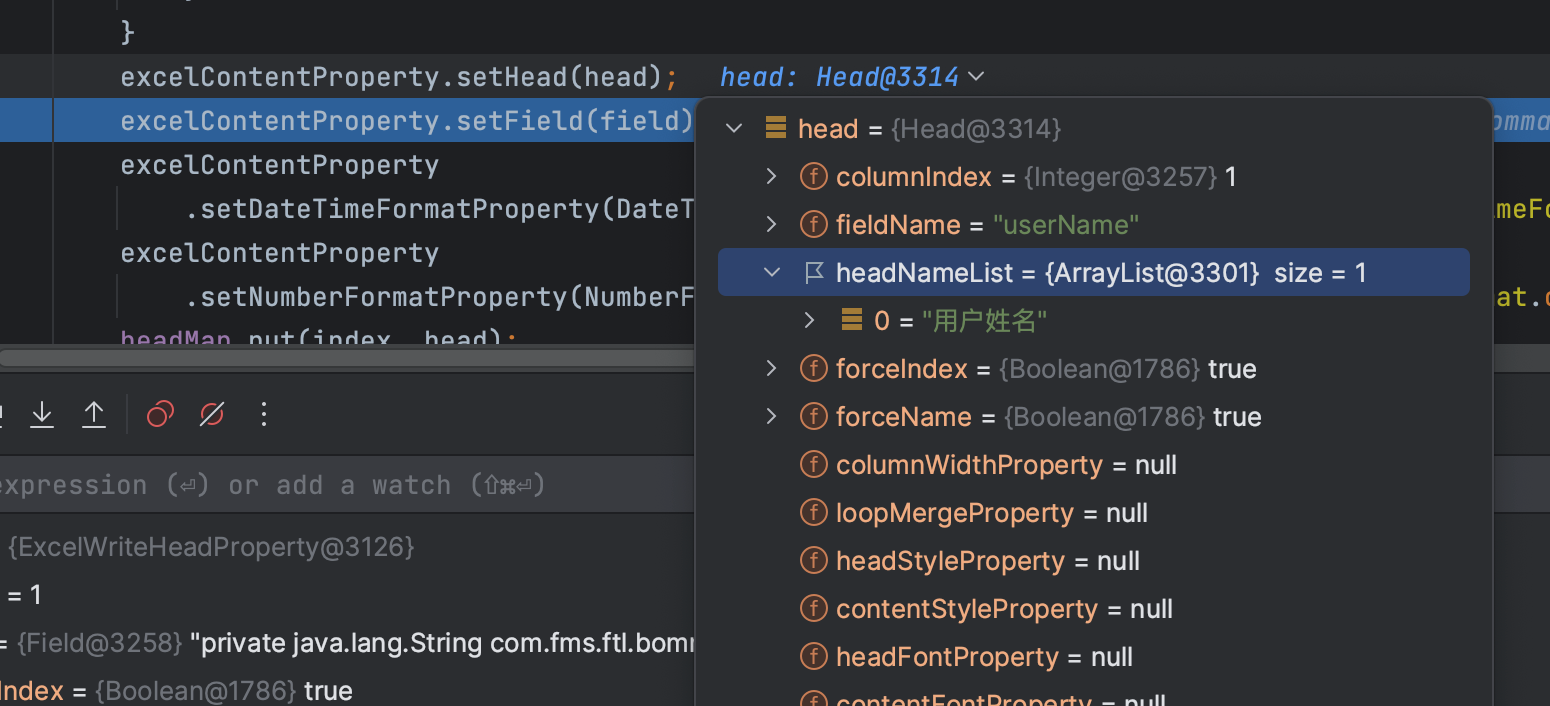
里面还是正常的,这也很正常,因为我全部字段都加了@ExcelProperty
没得到什么有用的信息,我们还是不知道为什么出了错,不过起码我们知道这几个属性类了 (给自己点精神鼓励好吧)
我们再重新回到AbstractWriteHolder的构造参数中,继续去看
// Initialization Annotation
initAnnotationConfig(handlerList, writeBasicParameter);
看一眼初始化注解配置做了什么
protected void initAnnotationConfig(List<WriteHandler> handlerList, WriteBasicParameter writeBasicParameter) {
if (!HeadKindEnum.CLASS.equals(getExcelWriteHeadProperty().getHeadKind())) {
return;
}
if (writeBasicParameter.getClazz() == null) {
return;
}
Map<Integer, Head> headMap = getExcelWriteHeadProperty().getHeadMap();
boolean hasColumnWidth = false;
boolean hasStyle = false;
for (Head head : headMap.values()) {
if (head.getColumnWidthProperty() != null) {
hasColumnWidth = true;
}
if (head.getHeadStyleProperty() != null || head.getHeadFontProperty() != null
|| head.getContentStyleProperty() != null || head.getContentFontProperty() != null) {
hasStyle = true;
}
dealLoopMerge(handlerList, head);
}
if (hasColumnWidth) {
dealColumnWidth(handlerList);
}
if (hasStyle) {
dealStyle(handlerList);
}
dealRowHigh(handlerList);
dealOnceAbsoluteMerge(handlerList);
}
内部逻辑很简单,headMap还是我们刚刚进行设置的,这里拿到的head就是存放的头都信息
Map<Integer, Head> headMap = getExcelWriteHeadProperty().getHeadMap();
然后就是设置样式之类的东西,这里我们不需要关注这些,所以这个方法也不是关键
回到addContent 继续看context.currentTable(writeTable);
public void currentTable(WriteTable writeTable) {
if (writeTable == null) {
return;
}
if (writeTable.getTableNo() == null || writeTable.getTableNo() <= 0) {
writeTable.setTableNo(0);
}
if (writeSheetHolder.getHasBeenInitializedTable().containsKey(writeTable.getTableNo())) {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Table:{} is already existed", writeTable.getTableNo());
}
writeTableHolder = writeSheetHolder.getHasBeenInitializedTable().get(writeTable.getTableNo());
writeTableHolder.setNewInitialization(Boolean.FALSE);
currentWriteHolder = writeTableHolder;
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("CurrentConfiguration is writeTableHolder");
}
return;
}
initCurrentTableHolder(writeTable);
// Workbook and sheet handler need to supplementary execution
WriteHandlerUtils.beforeWorkbookCreate(this, true);
WriteHandlerUtils.afterWorkbookCreate(this, true);
WriteHandlerUtils.beforeSheetCreate(this, true);
WriteHandlerUtils.afterSheetCreate(this, true);
initHead(writeTableHolder.excelWriteHeadProperty());
} public void currentTable(WriteTable writeTable) {
if (writeTable == null) {
return;
}
if (writeTable.getTableNo() == null || writeTable.getTableNo() <= 0) {
writeTable.setTableNo(0);
}
if (writeSheetHolder.getHasBeenInitializedTable().containsKey(writeTable.getTableNo())) {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Table:{} is already existed", writeTable.getTableNo());
}
writeTableHolder = writeSheetHolder.getHasBeenInitializedTable().get(writeTable.getTableNo());
writeTableHolder.setNewInitialization(Boolean.FALSE);
currentWriteHolder = writeTableHolder;
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("CurrentConfiguration is writeTableHolder");
}
return;
}
initCurrentTableHolder(writeTable);
// Workbook and sheet handler need to supplementary execution
WriteHandlerUtils.beforeWorkbookCreate(this, true);
WriteHandlerUtils.afterWorkbookCreate(this, true);
WriteHandlerUtils.beforeSheetCreate(this, true);
WriteHandlerUtils.afterSheetCreate(this, true);
initHead(writeTableHolder.excelWriteHeadProperty());
}
继续分析,不过有些我们已经不需要看了,这些都是用来触发handler相关的内容,用于自定义实现WriteHandler和WorkbookWriteHandler的相关逻辑,就不带大家过多关注无用的东西了
WriteHandlerUtils.beforeWorkbookCreate(this, true); WriteHandlerUtils.afterWorkbookCreate(this, true); WriteHandlerUtils.beforeSheetCreate(this, true); WriteHandlerUtils.afterSheetCreate(this, true);
设置writeTable到当前属性,不关心,继续。我看到了什么 哦 天呐 Row,我的宝贝 你终于出来了

initHead(writeTableHolder.excelWriteHeadProperty());
public void initHead(ExcelWriteHeadProperty excelWriteHeadProperty) {
if (!currentWriteHolder.needHead() || !currentWriteHolder.excelWriteHeadProperty().hasHead()) {
return;
}
int newRowIndex = writeSheetHolder.getNewRowIndexAndStartDoWrite();
newRowIndex += currentWriteHolder.relativeHeadRowIndex();
// Combined head
if (currentWriteHolder.automaticMergeHead()) {
addMergedRegionToCurrentSheet(excelWriteHeadProperty, newRowIndex);
}
for (int relativeRowIndex = 0, i = newRowIndex; i < excelWriteHeadProperty.getHeadRowNumber()
+ newRowIndex; i++, relativeRowIndex++) {
WriteHandlerUtils.beforeRowCreate(this, newRowIndex, relativeRowIndex, Boolean.TRUE);
Row row = WorkBookUtil.createRow(writeSheetHolder.getSheet(), i);
WriteHandlerUtils.afterRowCreate(this, row, relativeRowIndex, Boolean.TRUE);
addOneRowOfHeadDataToExcel(row, excelWriteHeadProperty.getHeadMap(), relativeRowIndex);
WriteHandlerUtils.afterRowDispose(this, row, relativeRowIndex, Boolean.TRUE);
}
}
看到 row 就知道有戏了, row和cell是poi的基础类,用来控制行和列的。但很遗憾,这还是填充头部的字段,并不是填充内容的相关逻辑,所以我们还需要继续,不过进步已经很大了。。

然后就到了addContent的第三步 add
public void add(List data) {
if (CollectionUtils.isEmpty(data)) {
data = new ArrayList();
}
WriteSheetHolder writeSheetHolder = writeContext.writeSheetHolder();
int newRowIndex = writeSheetHolder.getNewRowIndexAndStartDoWrite();
if (writeSheetHolder.isNew() && !writeSheetHolder.getExcelWriteHeadProperty().hasHead()) {
newRowIndex += writeContext.currentWriteHolder().relativeHeadRowIndex();
}
// BeanMap is out of order,so use sortedAllFiledMap
Map<Integer, Field> sortedAllFiledMap = new TreeMap<Integer, Field>();
int relativeRowIndex = 0;
for (Object oneRowData : data) {
int n = relativeRowIndex + newRowIndex;
addOneRowOfDataToExcel(oneRowData, n, relativeRowIndex, sortedAllFiledMap);
relativeRowIndex++;
}
}
这里我们重点看一下addOneRowOfDataToExcel
从名字也能听出来,这里就是真正赋值的地方,也就是row内容填充,就在这里
private void addJavaObjectToExcel(Object oneRowData, Row row, int relativeRowIndex,
Map<Integer, Field> sortedAllFiledMap) {
WriteHolder currentWriteHolder = writeContext.currentWriteHolder();
BeanMap beanMap = BeanMap.create(oneRowData);
Set<String> beanMapHandledSet = new HashSet<String>();
int cellIndex = 0;
// If it's a class it needs to be cast by type
if (HeadKindEnum.CLASS.equals(writeContext.currentWriteHolder().excelWriteHeadProperty().getHeadKind())) {
Map<Integer, Head> headMap = writeContext.currentWriteHolder().excelWriteHeadProperty().getHeadMap();
Map<Integer, ExcelContentProperty> contentPropertyMap =
writeContext.currentWriteHolder().excelWriteHeadProperty().getContentPropertyMap();
for (Map.Entry<Integer, ExcelContentProperty> entry : contentPropertyMap.entrySet()) {
cellIndex = entry.getKey();
ExcelContentProperty excelContentProperty = entry.getValue();
String name = excelContentProperty.getField().getName();
if (!beanMap.containsKey(name)) {
continue;
}
Head head = headMap.get(cellIndex);
WriteHandlerUtils.beforeCellCreate(writeContext, row, head, cellIndex, relativeRowIndex, Boolean.FALSE);
Cell cell = WorkBookUtil.createCell(row, cellIndex);
WriteHandlerUtils.afterCellCreate(writeContext, cell, head, relativeRowIndex, Boolean.FALSE);
Object value = beanMap.get(name);
CellData cellData = converterAndSet(currentWriteHolder, excelContentProperty.getField().getType(), cell,
value, excelContentProperty, head, relativeRowIndex);
WriteHandlerUtils.afterCellDispose(writeContext, cellData, cell, head, relativeRowIndex, Boolean.FALSE);
beanMapHandledSet.add(name);
}
}
// Finish
if (beanMapHandledSet.size() == beanMap.size()) {
return;
}
Map<String, Field> ignoreMap = writeContext.currentWriteHolder().excelWriteHeadProperty().getIgnoreMap();
initSortedAllFiledMapFieldList(oneRowData.getClass(), sortedAllFiledMap);
for (Map.Entry<Integer, Field> entry : sortedAllFiledMap.entrySet()) {
cellIndex = entry.getKey();
Field field = entry.getValue();
String filedName = field.getName();
boolean uselessData = !beanMap.containsKey(filedName) || beanMapHandledSet.contains(filedName)
|| ignoreMap.containsKey(filedName);
if (uselessData) {
continue;
}
Object value = beanMap.get(filedName);
WriteHandlerUtils.beforeCellCreate(writeContext, row, null, cellIndex, relativeRowIndex, Boolean.FALSE);
Cell cell = WorkBookUtil.createCell(row, cellIndex);
WriteHandlerUtils.afterCellCreate(writeContext, cell, null, relativeRowIndex, Boolean.FALSE);
CellData cellData = converterAndSet(currentWriteHolder, value == null ? null : value.getClass(), cell,
value, null, null, relativeRowIndex);
WriteHandlerUtils.afterCellDispose(writeContext, cellData, cell, null, relativeRowIndex, Boolean.FALSE);
}
}
哦吼,好像发现一点不太一样的地方

我们来看第一次根据contentPropertyMap执行完成以后的结果,beanMapHandledSet的结果是我们想要得的
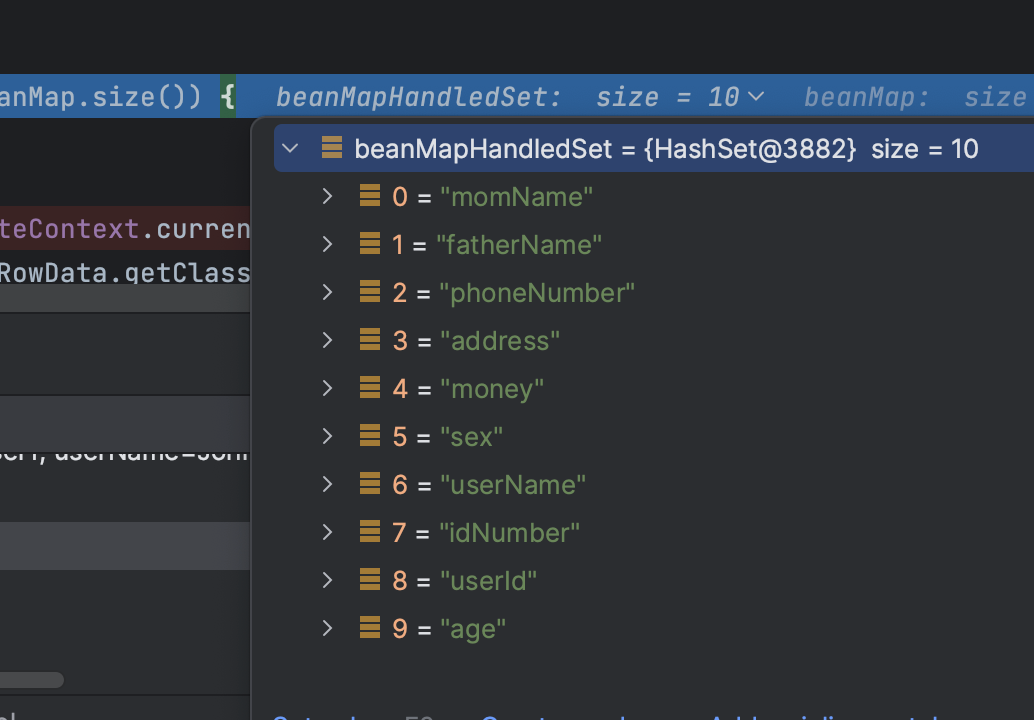
包括beanMap的值的映射,好像也没错???
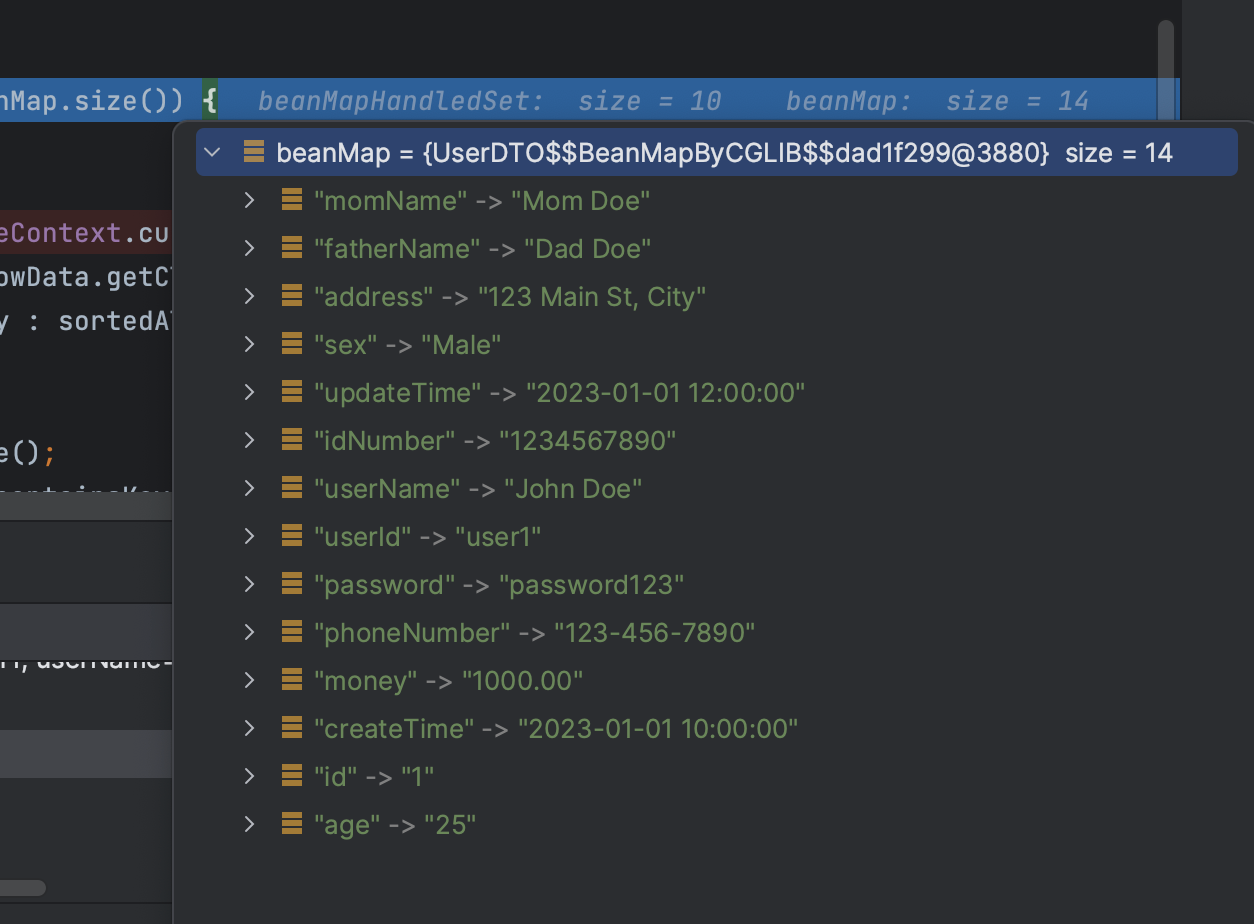
看起来都是很正常的,从Cells也能看出来
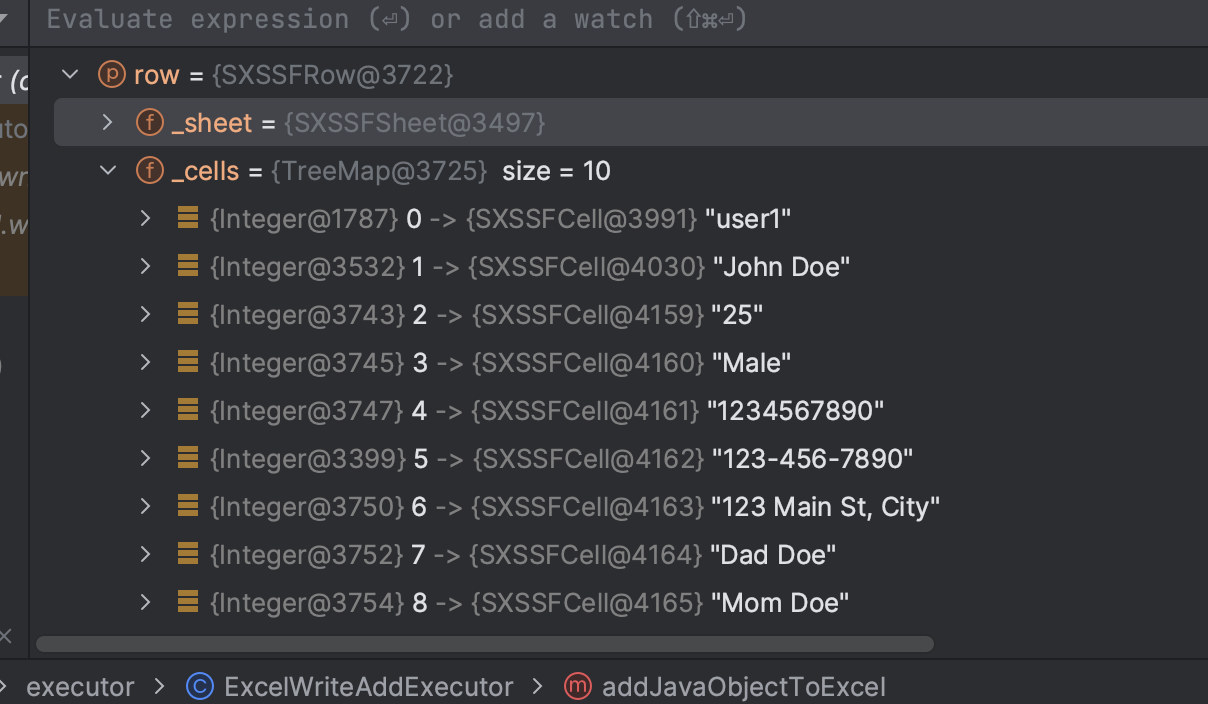
这时候我彻底懵逼了,这结果是对的呀,是我想要的,为什么 最后导出的时候是错误的,别急 继续往下看,神奇的点就在这里
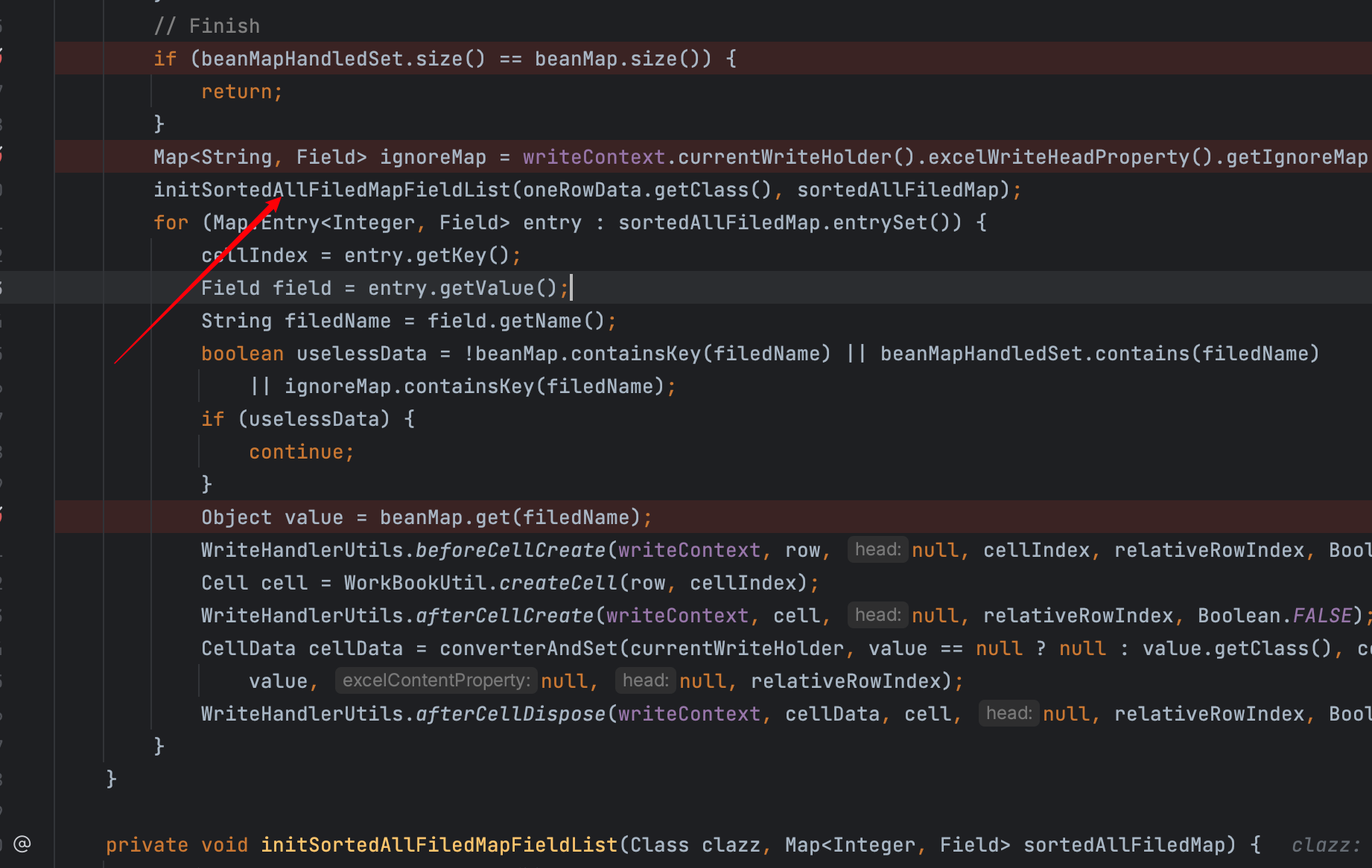
initSortedAllFiledMapFieldList 将oneRowData.getClass()的字段值又拿到了sortedAllFiledMap 中
最后根据sortedAllFiledMap 在进行遍历循环填充值。
这还真是小母猪戴🐻罩,一套又一套
我不禁沉思,为什么要再把rowData里的字段给拿出来呢?到这里已经明白了,为什么会导致错误了。。
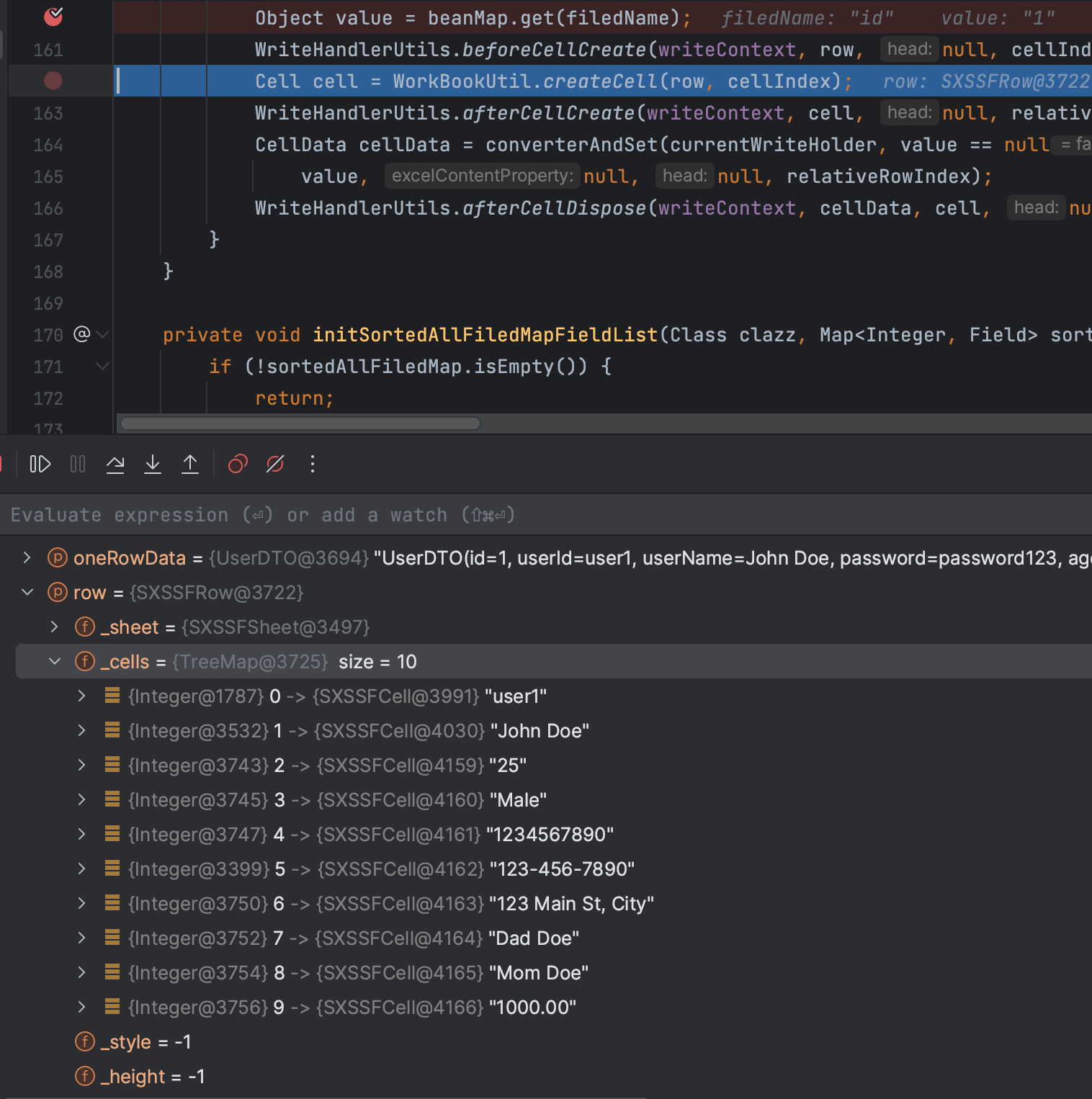
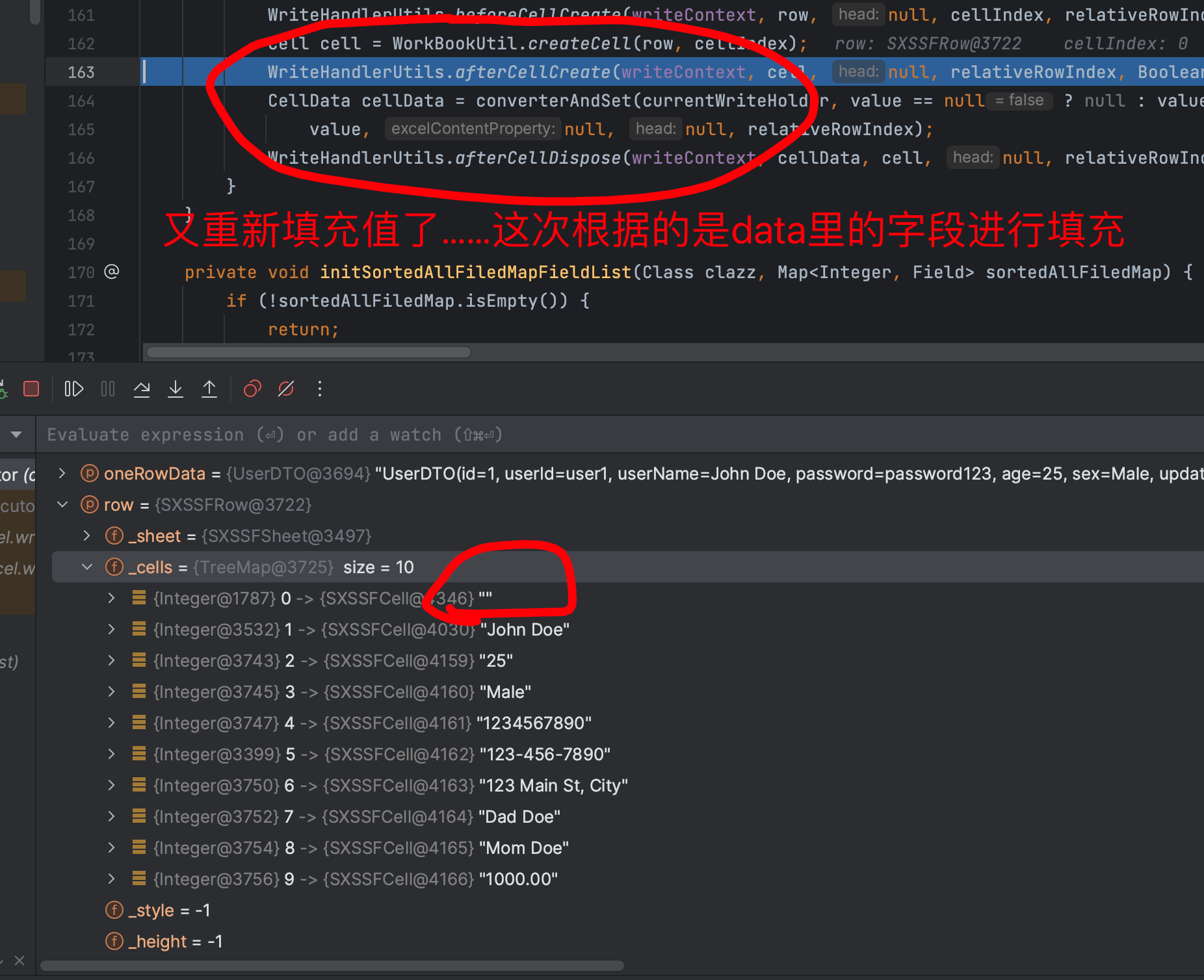
一切,都真相大白了,然而我已经彻底傻眼了,我完全没搞懂easyExcel的这波操作,为什么会这么玩
不过已经知道原因就好搞了,最后的更改措施就是将
List<UserDTO> 转换为 List<UserExcelVo>即可
两个小时,终于定位到问题了,我也说不上来是easyExcel的问题还是什么,确实反人类,今天又是元气大伤的一天!